Как и для чего можно использовать семантическое ядро конкурентов? Сбор семантики для контекстной рекламы — руководство от Ильи Исерсона Что такое базис и как искать запросы.
Мы уже не раз рассказывали, как можно составить семантическое ядро для сайта самостоятельно и даже написали книгу (кстати, вы можете ее скачать совершенно бесплатно). Прежде чем пытаться собрать ключевые слова с помощью сервисов, озвученных в настоящей статье, рекомендую прочитать книгу, чтобы понимать основы.
Процесс сбора семантики очень трудоемкий, требующий большого количества времени, особенно у новичков.
Существует много специализированных сервисов и программ для составления семантического ядра. Самые популярные: Яндекс.Вордстат и Google KeywordPlanner, Key Collector, Slovoeb, Megaindex.com, SEMRush, Just Magic, Топвизор и другие.
Многие из этих продуктов платные, у каждого из них есть свои преимущества и недостатки. Ниже детально рассмотрим 2 помощника для сбора семантики сайта – один платный, другой бесплатный.
Rush Analytics – онлайн-сервис для создания семантического ядра
Позволяет автоматизировать все рутинные процессы при сборе семантики: от подбора ключей до кластеризации.
Плюсы:
- Не требуется установка софта.
- Понятный и простой интерфейс.
- Наличие руководств по использованию сервиса и подсказок на каждом этапе.
- В отчетах о кластеризации есть много полезных данных, которые можно использовать для создания контента.
- Можно расширить семантическое ядро с помощью инструмента «Поисковые подсказки».
Минусы:
Из минусов можно отметить, что это полностью платный сервис. Только при регистрации вам начисляется бонус в 200 рублей. Если у вас большой объем работ – вам это обойдется недешево. К примеру, кластеризация одного ключевого запроса стоит 50 копеек.
Сбор ключевых слов
После простой регистрации будет доступно 4 инструмента для работы с ключевыми словами: «Wordstat», «Сбор подсказок», «Кластеризация» и «Проверка ключевых слов».
Теперь можно приступить к сбору ключевиков, для этого необходимо создать новый проект:
В открывшейся вкладке указываем название проекта и регион:

Следующий шаг – это Настройки сбора. Здесь нужно выбрать, каким способом будут собраны слова:
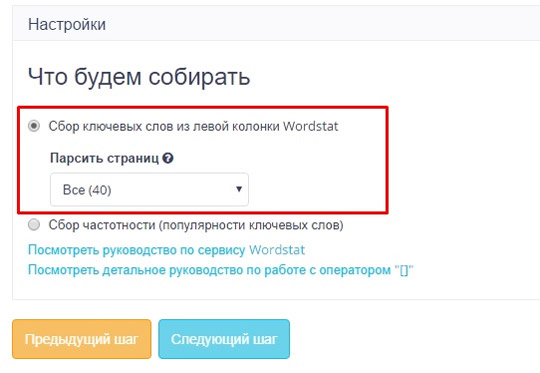
Для работы мы выберем первый вариант: сбор ключевых слов из левой колонки Wordstat.
Третий шаг – Ключевые слова и цена. Указываем базовые ключевые слова сайта либо списком, либо загружаем файл.
Например, у нас сайт про аренду спецтехники. Вписываем главные ключи «аренда спецтехники», «аренда крана», «услуги крана». Этого будет достаточно для сбора семантики.

Также указываем стоп-слова. Они помогут отфильтровать ваш список и сэкономить время и средства. Есть удобная функция «Стоп-слова по тематикам».
Для нашего сайта добавим стоп-слова «договор», «работа».
Через некоторое время наш проект будет готов:

Теперь можно скачать файл в формате xlsx:

Мы получили довольно большой список ключевых запросов (1084 слов). Некоторые из них лишние, поэтому лучше пробежаться по списку и удалить ненужные слова.
Определение частотности
Для этого создаем новый проект (указываем название и регион), во второй вкладке выбираем «Сбор частотности», отмечаем первые три варианта:


Как закончится сбор частотности, можно скачать файл. Смотрим, что получилось. О том, как спрогнозировать трафик по ключевым словам, мы уже писали, если еще не читали – прочитайте обязательно.
Скажу только, что не советую использовать для продвижения запросы-пустышки, т.е. слова, по которым частота с операторами «!Ключ» равна нулю.
Кластеризация ключевых фраз
Кластеризация – разбивка ключевых слов на группы с точки зрения логики и на основе выдачи поисковых систем. После распределения запросов на группы вы получите, по сути, готовую структуру сайта.
Для этого нажимаем на «Кластеризацию» и создаем новый проект:

Называем проект «Спецтехника3» (любое название на ваш выбор), выбираем поисковую систему (мы выбрали Яндекс), также указываем регион:

Следующий шаг – настройка сбора. Для начала нужно выбрать тип алгоритма кластеризации. Данные алгоритмы работают по одному и тому же принципу (сравнение ТОПов поисковиков), но предусмотрены для решения разных задач:
- Wordstat – подходит для создания структуры сайта.
- Ручные маркеры – подходит, если у вас уже есть готовая структура сайта, и вам нужны ключевые слова, по которым нужно продвигать имеющиеся страницы сайта.
- Комбинированный (ручные маркеры + Wordstat) – подходит для задачи одновременного подбора ключевых слов для существующей структуры сайта и ее расширения.
Здесь же указываем минимальную частотность, которую используем, и точность кластеризации:

Чем больше точность кластеризации, тем большее количество ключей попадут в одну группу. Для блогов и порталов точность не так важна (можно поставить 3 или 4). Но для сайтов с конкурентными тематиками лучше выбирать более высокую точность группировки.
Как видно из скриншота, мы выбрали все допустимые точности группировки. На цену кластеризации это не влияет, зато мы сможем определить какая группа нам больше подходит.
Приступаем к следующему этапу – загрузке файла с ключевыми словами:

Результат кластеризации в формате xlsx выглядит следующим образом:

Нас основе этого файла можно составлять Карту релевантности, формировать ТЗ для копирайтеров.
Программа Slovoeb
Одна из лучших бесплатных программ для составления семантического ядра. Многие ее называют «младший брат Key Collector».
Плюсы:
- Программа абсолютно бесплатная.
- Наличие подсказок, описание программы и ее инструментов.
- Понятный интерфейс.
Минусы:
- Требует установки на компьютер.
- Нет автоматической кластеризации запросов.
- Нет обновлений программы.
Настройка программы
Заказать разработку СЯ и карты можно (ищите в разделе «Оптимизация и техническое сопровождение»).
Добрый день, друзья.
Наверняка вы уже забыли вкус моих статей. Предыдущий материал был довольно давно, хотя и обещал я публиковать статьи чаще, чем обычно.
В последнее время увеличилось количество работы. Создал новый проект (информационный сайт), занимался его версткой, дизайном, собирал семантическое ядро и начал публиковать материал.
Сегодня же будет очень объемный и важный материал для тех, кто ведет свой сайт более 6-7 месяцев (в некоторых тематиках более 1 года) имеет большое количество статей (в среднем 100) и еще не достиг планки минимум в 500-1000 посещений в сутки. Цифры взяты по минимуму.
Важность семантического ядра
В некоторых случаях слабый рост сайта вызван неправильной технической оптимизацией сайта. Больше случаев, когда контент некачественный. Но еще больше случаев, когда тексты пишутся вообще не под запросы - материалы никому не нужны. Но имеется еще и очень огромная часть людей, которая создает сайт, все правильно оптимизирует, пишет качественные тексты, но спустя 5-6 месяцев сайт только начинает набирать первые 20-30 посетителей с поиска. Небольшими темпами через год это уже 100-200 посетителей и цифра в доходах равняется нулю.
И хотя, все сделано правильно, нет никаких ошибок, а тексты порой даже в разы качественней конкурентов, но вот как-то не идет, хоть убей. Начинаем списывать этот косяк на отсутствие ссылок. Конечно ссылки дают буст в развитии, но это не самое главное. И без них можно через 3-4 месяца иметь 1000 посещений на сайте.
Многие скажут, что это все треп и так быстро такие цифры не получишь. Но если мы посмотрим, то не достигаются такие цифры именно на блогах. Информационные же сайты (не блоги), созданные для быстрого заработка и окупаемости вложений, примерно через 3-4 месяца вполне реально выходят на суточную посещаемость в 1000 человек, а через год – 5000-10000. Цифры конечно зависят от конкурентности ниши, ее объема и объема самого сайта на указанный срок. Но, если взять нишу с довольно небольшой конкуренцией и объемом в 300-500 материалов, то такие цифры за указанные сроки вполне достижимы.
Почему же именно блоги не достигают таких быстрых результатов? Главнейшей причиной является отсутствие семантического ядра. Из-за этого статьи пишут всего под один какой-то запрос и практически всегда под очень конкурентный, что не дает странице выбиться в ТОП за короткие сроки.
На блогах, как правило, статьи пишут по подобию конкурентов. Имеем 2- читаемых блога. Видим, что у них посещаемость приличная, начинаем анализировать их карту сайта и публиковать тексты под те же самые запросы, которые уже переписаны сотнями раз и очень конкурентные. В итоге получаем очень качественный контент на сайте, но в поиске он себя чувствует плохо, т.к. требует большого возраста. Бьемся об голову, почему же мой контент лучший, но в ТОП не пробивается?
Именно поэтому я решил написать подробный материал про семантическое ядро сайта, чтобы вы могли собрать себе список запросов и что немало важно – писали тексты под такие группы ключевых слов, которые без покупки ссылок и всего за 2-3 месяца выходили в ТОП (конечно, если контент качественный).
Материал для большинства будет сложный, если ни разу не сталкивались с этим вопросом в его правильном ключе. Но тут главное начать. Как только начинаете действовать, все сразу становится ясно.
Сделаю очень важное замечание. Касается оно тех, кто не готов вкладываться в качество своими кровными заработанными монетами и всегда пытается находить бесплатные лазейки. Семантику бесплатно качественно не соберешь и это известный факт. Поэтому, в данной статье я описываю процесс сбора семантики максимального качества. Никаких бесплатных способов или лазеек именно в этом посте не будет! Обязательно будет новый пост, где расскажу про бесплатные и другие инструменты, с помощью которых вы сможете собрать семантику, но не в полном объеме и без должного качества. Поэтому, если вы не готовы вкладываться в основу основ для вашего сайта, тогда данный материал вам ни к чему!
Несмотря на то, что практически каждый блоггер пишет статью о сем. ядре, могу с уверенностью сказать, что нет нормальных бесплатных пособий в интернете по данной теме. А если и есть, то нет такого, которое бы в полной картине давало понятие, что же должно получится на выходе.
Чаще всего ситуация заканчивается тем, что какой-то новичок пишет материал и рассказывает о сборе семантического ядра, как о применении сервиса для сбора статистика поисковых запросов от Яндекс (wordstat.yandex.ru). В конечном итоге необходимо зайти на этот сайт, вбить запросы по вашей теме, сервис выдаст список фраз, входящих в ваш вбитый ключ – это и есть вся методика.
Но на самом деле семантическое ядро собирается не так. В описанном выше случае у вас попросту не будет семантического ядра. Вы получите какие-то оторванные запросы и все они будут об одном и том же. Например, возьмем мою нишу «сайтостроение».
Какие главные запросы можно по ней без раздумий назвать? Вот лишь некоторые:
- Как создать сайт;
- Раскрутка сайта;
- Создание сайта;
- Продвижение сайта и т.д.
Запросы получаются об одном и том же. Смысл их сводится лишь к 2м понятиям: создание и раскрутка сайта.
После такой проверки сервис wordstat выдаст очень много поисковых запросов, которые входят в главные запросы и они также будут об одном и том же. Единственное их различие будет в измененных словоформах (добавление некоторых слов и изменение расположения слов в запросе с изменением окончаний).
Конечно, определенное количество текстов написать получится, так как запросы могут быть разные даже в данном варианте. Например:
- Как создать сайт wordpress;
- Как создать сайт joomla;
- Как создать сайт на бесплатном хостинге;
- Как раскрутить сайт бесплатно;
- Как раскрутить сайт сервис и т.д.
Очевидно, что под каждый запрос можно выделить отдельный материал. Но такое составление семантического ядра сайта не увенчается успехом, т.к. не будет полноты раскрытия информации на сайте в выбранной нише. Весь контент будет лишь о 2х темах.
Иногда блоггеры-новички описывают процесс составления семантического ядра, как анализ отдельных запросов в сервисе анализа запросов Яндекс Вордстат. Вбиваем какой-то отдельный запрос, относящийся не к теме в целом, а лишь к определенной статье (например, как оптимизировать статью), получаем по нему частотность и вот оно – семантическое ядро собирается. Получается, что таким образом мы должны умственно определить всевозможные темы статей и проанализировать их.
Оба вышеописанные варианты неправильные, т.к. не дают полного семантического ядра и заставляют постоянно возвращаться к его составлению (второй вариант). К тому же вы не будете иметь на руках вектор развития сайта и не сможете в первую очередь публиковать материалы, которые и нужно размещать в числе первых.
Касаемо первого варианта, то покупая когда-то курсы по раскрутке сайтов, я постоянно видел именно такое объяснение сбора ядра запросов для сайта (вбить главные ключ и скопировать все запросы из сервиса в текстовый документ). В итоге меня постоянно мучал вопрос «А что же делать с такими запросами?» На ум приходило следующее:
- Писать много статей об одном и том же, но употребляя разные ключевые слова;
- Все эти ключи вписывать в поле description к каждому материалу;
- Вписать все ключи из сем. ядра в общее поле description ко всему ресурсу.
Ни одно из этих предположений не было верным, как в общем-то и само составленное семантическое ядро сайта.
На окончательном варианте сбора семантического ядра мы должны получит не просто список запросов в количестве 10000, например, а иметь на руках список групп запросов, каждая из которых используется для отдельной статьи.
Группа может содержать от 1 до 20-30 запросов (иногда 50, а то и больше). В таком случае в тексте мы употребляем все эти запросы и страница в перспективе ежедневно будет приносить трафик по всем запросам, если попадет на 1-3 позиции в поиске. Кроме этого, каждая группа должна иметь свою конкуренцию, чтобы знать, имеет ли смысл сейчас публиковать по ней текст или нет. Если конкуренция большая, тогда можем ожидать эффект от страницы только через 1-1.5 года и с проведением регулярных работ по ее продвижению (ссылки, перелинковка и т.д.). Поэтому, лучше на такие тексты делать упор в самую последнюю очередь, даже если они самые трафиковые.
Ответы на возможные вопросы
Вопрос №1. Понятно, что на выходе получаем группу запросов для написания текста, а не всего один ключ. Не будут ли похожи в этом случае ключи между собой и почему бы под каждый запрос не написать отдельный текст?
Вопрос №2. Известно, что каждая страница должна затачиваться лишь под один ключевик, а тут мы получаем целую группу да еще в некоторых случаях с достаточно большим содержанием запросов. Как в таком случае происходит оптимизация самого текста, ведь если ключей, например, 20, тогда употребление хотя бы по одному разу каждого в тексте (даже большого размера) уже похоже на текст для поисковика, а не для людей.
Ответ. Если взять пример запросов из предыдущего вопроса, то затачиваться материал первым делом будет именно под самый частотный (1й) запрос, так как мы большего всего заинтересованы в его выходе на топовые позиции. Данный ключевик мы и считаем главным в этой группе.
Оптимизация под главную ключевую фразу происходит также, как бы это и делалось при написании текста лишь под один ключ (ключ в заголовке title, употребление нужного количества символов в тексте и нужного количества раз самого ключа, если требуется).
Касаемо других ключей, то мы их также вписываем, но не слепо, а на основе анализа конкурентов, который может показать среднее значение количества этих ключей в текстах из ТОПа. Может получиться ситуация, что для большинства ключевиков вы получите нулевые значения, а значит в точном вхождении они не требуют употребления.
Таким образом текст пишется, употребляя всего лишь главный запрос в тексте в прямом. Конечно другие запросы тоже могут быть употреблены, если анализ конкурентов покажет их наличие в текстах из ТОП. Но это никак не 20 ключевиков в тексте в их точном вхождении.
Совсем недавно публиковал материал под группу из 11 ключей. Вроде бы много запросов, но на скриншоте ниже можете видеть, что лишь главный самый частотный ключ имеет употребление точного вхождения – 6 раз. Остальные же ключевые фразы не имеют точных вхождений, но также и разбавочных (на скриншоте не видно, но в ходе анализа конкурентов это показано). Т.е. они вообще не употребляются.
(1я колонка – частотность, 2я – конкурентность, 3я – количество показов)
В большинстве случаев будет похожая ситуация, когда лишь пару ключей нужно будет употребить в точном вхождении, а все остальные либо сильно разбавлять, либо вообще не употреблять даже в разбавочном вхождении. Статья получается читаемой и нет намеков на заточку только под поиск.
Вопрос №3. Вытекает из ответа на Вопрос №2. Если остальные ключи в группе не нужно вообще употреблять, то как тогда они будут получать трафик?
Ответ. Дело в том, что по наличию определенных слов в тексте поисковик может определить о чем текст. Так как в ключевых словах имеются определенные отдельные слова, относящиеся только к этому ключу, то их и нужно употреблять в тексте определенное количество раз на основе того же анализа конкурентов.
Таким образом ключ в точном вхождении не употребится, а вот слова из ключа по отдельности в тексте присутствовать будут и в ранжировании также будут принимать участие. В итоге по этим запросам текст будет также находиться в поиске. Но и количество отдельных слов в этом случае в идеале требуется соблюдать. Помогут конкуренты.
На основные вопросы, которые могли загнать вас в ступор, я ответил. Подробнее, как оптимизировать текст под группы запросов, я напишу в одном из следующим материалов. Там будет и про анализ конкурентов и про написание самого текста под группу ключей.
Ну, а если вопросы еще остались, тогда задавайте свои комментарии. На все отвечу.
А теперь давайте начнем составление семантического ядра сайта.
Очень важно. Весь процесс, как он есть на самом деле я никак не смогу описать в этой статье (придется делать целый вебинар на 2-3 часа или мини-курс), поэтому я постараюсь быть краток, но в то же время информативным и затронуть максимальное количество моментов. Например, я не буду описывать в детальности настройку софта KeyCollector. Все будет урезано, но максимально понятно.
Теперь пройдемся по каждому пункту. Начнем. Сначала подготовка.
Что необходимо для сбора семантического ядра?

Перед тем, как составить семантическое ядро сайта, настроим кейколлектор для правильного сбора статистики и парсинга запросов.
Настройка KeyCollector
Войти в настройки можно, нажав на пиктограмму в верхнем меню софта.

Сначала то, что касается парсинга.
Хочу отметить настройки «Количество потоков» и «Использовать основной IP-адрес». Количество потоков для сбора одного небольшого ядра не нужно большое. Достаточно 2-4 потоков. Чем больше потоков, тем больше нужно прокси-серверов. В идеале 1 прокси на 1 поток. Но можно и 1 прокси на 2 потока (так парсил я).
Касаемо второй настройки, то в случае парсинга в 1-2 потока можно использовать свой основной ИП адрес. Но только,если он динамический, т.к. в случае бана статического ИП вы потеряете доступ к поисковой системе Яндекс. Но все же приоритет всегда отдается использованию прокси-сервера, так как лучше обезопасить себя.
На вкладке настроек парсинга Yandex.Direct важно добавить свои аккаунты Яндекса. Чем их будет больше, тем лучше. Можете их зарегистрировать сами или купить, как я писал ранее. Я же их приобретал, так как мне проще потратить 100 рублей за 30 аккаунтов.
Добавление можно выполнить из буфера, заранее скопировав список аккаунтов в нужном формате, или загрузить из файла.
Аккаунты нужно указывать в формате «логин:пароль» при этом в логине не указывать сам хост (без @yandex.ru). Например, «artem_konovalov:jk8ergvgkhtf».
Также, если мы используем несколько прокси-серверов, лучше закрепить их за определенными аккаунтами. Подозрительно будет, если сначала запрос идет с одного сервера и с одного аккаунта, а при следующем запросе с этого же акаунта яндекса прокси сервер уже другой.
Рядом с аккаунтами имеется столбик «IP прокси». Напротив каждого аккаунта мы и вписываем определенный прокси. Если аккаунтов 20, а прокси-серверов 2, тогда будет 10 аккаунтов с одним прокси и 10 с другим. Если 30 аккаунтов, тогда 15 с один сервером и 15 с другим. Логику, думаю, вы поняли.
Если используем всего один прокси, то нет смысла вписывать его к каждому аккаунту.
Про количество потоков и использование основного ИП адреса я говорил немного ранее.
Следующая вкладка «Сеть», на которой нужно внести прокси-сервера, которые будут использоваться для парсинга.
Вводить прокси нужно в самом низу вкладки. Можно загрузить их из буфера в нужном формате. Я же добавлял по простому. В каждую колонку строки я вписывал данные о сервере, дающиеся вам при его покупке.
Далее настраиваем параметры экспорта. Так как все запросы с их частотностями нам нужно получить в файле на компьютере, то необходимо выставить некоторые параметры экспорта, чтобы не было ничего лишнего в таблице.
В самом низу вкладки (выделил красным) нужно выбрать те данные, которые нужно экспортировать в таблицу:
- Фраза;
- Источник;
- Частотность «!» ;
- Лучшая форма фразы (можно и не ставить).
Осталось лишь настроить разгадывание антикапчи. Вкладка так и называется - «Антикапча». Выбираем используемый сервис и вводим специальный ключ, который находится в аккаунте сервиса.
Специальный ключ для работы с сервисом предоставляется в письме после регистрации, но также его можно взять из самого аккаунта в пункте «Настройки – настройки аккаунта».
На этом настройки KeyCollector выполнены. Не забываем после проделанных изменений сохранить настройки, нажав на большую кнопку внизу «Сохранить изменения».
Когда все сделано и мы готовы к парсингу, можно приступить к рассмотрению этапов сбора семантического ядра, а потом уже и проделать каждый этап в порядке очереди.
Этапы сбора семантического ядра
Получить качественное и полное семантическое ядро невозможно, используя лишь основные запросы. Также нужно анализировать запросы и материалы конкурентов. Поэтому весь процесс составления ядра состоит из нескольких этапов, которые в свою очередь еще делятся на подэтапы.
- Основа;
- Анализ конкурентов;
- Расширение готового списка с этапов 1-2;
- Сбор лучших словоформ к запросам с этапов 1-3.
Этап 1 – основа
В ходе сбора ядра на этом этапе нужно:
- Сформировать основной список запросов в нише;
- Расширение этих запросов;
- Чистка.
Этап 2 – конкуренты
В принципе, этап 1 уже дает некий объем ядра, но не в полной мере, т.к. мы можем что-то упустить. А конкуренты в нашей нише помогут найти упущенные дыры. Вот шаги, необходимые к выполнению:
- Сбор конкурентов на основе запросов с этапа 1;
- Парсинг запросов конкурентов (анализ карты сайта, открытая статистика liveinternet, анализ доменов и конкурентов в SpyWords);
- Чистка.
Этап 3 – расширение
Многие останавливаются уже на первом этапе. Кто-то доходит до 2го, но имеется же еще ряд дополнительных запросов, которые также могут дополнить семантическое ядро.
- Объединяем запросы с 1-2 этапов;
- Оставляем 10% самых частотных слов со всего списка, которые содержат минимум 2 слова. Важно, чтобы эти 10% были не более 100 фраз, т.к. большое количество заставит вас сильно закопаться в процесс сбора, чистки и группировки. Нам же нужно собрать ядро в соотношении скорость/качество (минимальные потери качества при максимальной скорости);
- Выполняем расширение этих запросов с помощью сервиса Rookee (все есть в KeyCollector);
- Чистим.
Этап 4 – сбор лучших словоформ
Сервис Rookee может для большинства запросов определить их лучшую (правильную) словоформу. Этим также нужно пользоваться. Целью не является определить то слово, которое более правильно, а найти еще некоторые запросы и их формы. Таким образом можно подтянуть еще пул запросов и использовать их при написании текстов.
- Объединение запросов с первых 3х этапов;
- Сбор по ним лучших словоформ;
- Добавление лучших словоформ в список ко всех запросам, объединенным с 1-3 этапов;
- Чистка;
- Экспорт готового списка в файл.
Как видите, все не так уж и быстро, а тем более не так просто. Это я обрисовал лишь нормальный план составления ядра, чтобы на выходе получить качественный список ключей и ничего не потерять или потерять по минимуму.
Теперь я предлагаю пройтись по каждому пункту в отдельности и проштудировать все от А до Я. Информации много, но это того стоит, если вам нужно действительно качественное семантическое ядро сайта.
Этап 1 – основа
Сперва мы формируем список основных запросов ниши. Как правило, это 1-3х словные фразы, которые описывают определенный вопрос ниши. В пример предлагаю взять нишу «Медицина», а конкретнее - поднишу сердечных заболеваний.
Какие основные запросы мы можем выделить? Все я конечно писать не буду, но парочку приведу.
- Заболевания сердца
- Инфаркт;
- Ишемическая болезнь сердца;
- Аритмия;
- Гипертония;
- Порок сердца;
- Стенокардия и т.д.
Простыми словами – это общие названия заболеваний. Таких запросов может быть достаточно много. Чем больше сможете сделать, тем лучше. Но не стоит вписывать для галочки. Бессмысленно выписывать более конкретные фразы от общих, например:
- Аритмия;
- Аритмия причины;
- Лечение аритмии;
- Аритмия симптомы.
Главной является лишь первая фраза. Остальные нет смысла указывать, т.к. они появятся в списке в ходе расширения с помощью парсинга из левой колонки Яндекс вордстат.
Для поиска общих фраз можно пользоваться, как сайтами конкурентов (карта сайта, названия разделов…), так и опытом специалиста в этой нише.

Парсинг займет некоторое время, в зависимости от количества запросов в нише. Все запросы по умолчанию помещаются в новую группу с названием «Новая группа 1», если память не изменяет. Я обычно переименовываю группы, чтобы понимать, какая за что отвечает. Меню управления группами находится справа от списка запросов.
Функция переименования находится в контекстном меню при нажатии правой кнопки мыши. Это меню понадобится еще для создания других групп на втором, третьем и четвертом этапах.
Поэтому, можете сразу добавить еще 3 группы, нажав на первую пиктограмму «+», чтобы группа создалась в списке сразу после предыдущей. Пока в них не нужно ничего добавлять. Пусть просто будут.
Называл я группы так:
- Конкуренты – понятно, что в этой группе находится список запросов, который я дособрал у конкурентов;
- 1-2 – это объединенный список запросов с 1го (основного списка запросов) и 2го (запросы конкурентов) этапов, чтобы оставить из них всего 10% запросов, состоящих минимум из 2х слов и собрать по ним расширения;
- 1-3 – объединенный список запросов с первого, второго и третьего (расширений) этапов. Также в эту группу мы собираем лучшие словоформы, хотя грамотней было бы собрать их в новую группу (например, лучшие словоформы), а затем после их чистки уже перенести в группу 1-3.
После окончания парсинга из yandex.wordstat вы получаете большой список ключевых фраз, который, как правило (ели ниша небольшая) будет в пределах нескольких тысяч. Много из этого является мусором и запросами-пустышками и придется все чистить. Что-то отсеем автоматически с помощью функционала KeyCollector, а что-то придется лопатить руками и немного посидеть.
Когда запросы все собраны, нужно собрать их точные частотности. Общая частотность собирается при парсинге, а вот точную нужно собирать отдельно.
Для сбора статистики по количеству показов можно пользоваться двумя функциями:
- С помощью Яндекс Директ – быстро, статистика собирается пачками, но имеются ограничения (например, фразы больше 7ми слов не прокатят и с символами тоже);
- С помощью анализа в Яндекс Вордстате – очень медленно, фразы анализируются по одной, но нет ограничений.
Сначала собрать статистику с помощью Директа, чтобы это было максимально быстро, а для тех фраз, по которым с Директом не получилось определить статистику, используем уже Вордстат. Как правило, таких фраз останется мало и они дособерутся быстро.
Сбор статистика показов с помощью Яндекс.Директ осуществляются при нажатии на соответствующую кнопку и назначении нужных параметров.
После нажатия на кнопку «Получить данные» может быть предупреждение, что Яндекс Директ не включен в настройках. Вам нужно будет согласиться на активацию парсинга с помощью Директа, чтобы начать определять статистику частотности.
Вы сразу увидите, как пачками в колонку «Частотность! » начнут проставляются точные показатели показов по каждой фразе.
Процесс выполнения задачи можно видеть на вкладке «Статистика» в самом низу программы. Когда задача будет выполнена, на вкладке «Журнал событий» вы увидите уведомление о завершении, а также исчезнет полоса прогресса на вкладке «Статистика».
После сбора количества показов с помощью Яндекс Директ мы проверяем, имеются ли фразы, для которых частотность не собралась. Для этого сортируем колонку «Частотность!» (нажимаем на нее), чтобы в верху стали наименьшие значения или наибольшие.
Если вверху будут все нули, тогда все частотности собранные. Если же будут пустые ячейки, тогда для этих фраз показы не определились. Тоже самое касается и при сортировке по убиванию, только тогда придется смотреть результат в самом низу списка запросов.
Начать сбор с помощью яндекс вордстат также можно, нажав на пиктограмму и выбрав необходимый параметр частотности.

После выбора типа частотности вы увидите, как постепенно начнут заполнятся пустые ячейки.
Важно: не стоит пугаться, если после конца процедуры останутся пустые ячейки. Дело в том, что пустыми они будут в случае их точной частотности менее 30. Это мы выставили в настройках парсинга в Keycollector. Эти фразы можно смело выделить (также, как и обычные файлы в проводнике Windows) и удалить. Фразы выделятся голубым цветом, нажимаем правую кнопку мышки и выбираем «Удалить выделенные строки».
Когда вся статистика собрана, можно приступить к чистке, которую очень важно делать на каждом этапе сбора семантического ядра.
Основная задача – убрать фразы не относящие к тематике, убрать фразы со стоп-словами и избавиться от слишком низкочастотных запросов.
Последнее в идеале не нужно выполнять, но, если мы будем в ходе составления сем. ядра использовать фразы даже с минимальной частотностью в 5 показов в месяц, то это увеличит ядро на процентов 50-60 (а может быть и все 80%) и заставить нас сильно закопаться. Нам же нужно получить максимальную скорость при минимальных потерях.
Если хотим получить максимально полное семантическое ядро сайта, но при этом собирать его около месяца (есть опыт совсем отсутствует), тогда берите частотности от 4-5 месячных показов. Но лучше (если новичок) оставлять запросы, которые имеют хотя бы 30 показов в месяц. Да, мы немного потеряем, но это цена за максимальную скорость. А уже в ходе роста проекта можно будет заново получить эти запросы и уже их использовать для написания новых материалов. И это только при условии, что все сем. ядро уже выписано и нет тем для статей.
Отфильтровать запросы по количеству их показов и другим параметрам позволяет все тот же кейколлектор на полном автомате. Изначально я рекомендую сделать именно это, а не удалять мусорные фразы и фразы со стоп-словами, т.к. гораздо проще будет это делать, когда общий объем ядра на этом этапе станет минимальным. Что проще, лопатить 10000 фраз или 2000?
Доступ к фильтрам находится на вкладке «Данные», нажав на кнопку «Редактировать фильтры».

Я рекомендую сначала отобразить все запросы с частотностью менее 30 и перенести их в новую группу, чтобы их не удалять, так как в будущем они могут пригодиться. Если же мы просто применим фильтр для отображения фраз с частотностью более 30, то после очередного запуска KeyCollector придется заново применять этот же фильтр, так как все сбрасывается. Конечно, фильтр можно сохранить, но все равно придется его применять, постоянно возвращаясь ко вкладке «Данные».
Чтобы избавить себя от этих действий, мы в редакторе фильтров добавляем условие, чтобы отображались фразы только с частотностью менее 30.



В будущем выбрать фильтр можно, нажав на стрелку возле пиктограммы дискеты.
Итак, после применения фильтра, в списке запросов останутся только фразы с частотностью менее 30, т.е. 29 и ниже. Также отфильтрованная колонка выделится цветом. В примере ниже вы будете видеть частотность только 30, т.к. я показываю все это на примере уже готово ядра и все почищено. На это внимания не обращайте. У вас все должно быть так, как я описываю в тексте.

Для переноса нужно выделить все фразы в списке. Нажимаем на первую фразу, Листаем в самый низ списка, зажимаем клавишу «Shift» и кликаем один раз на последнюю фразу. Таким образом выделяется все фразы и пометятся голубым фоном.
Появится небольшое окно, где необходимо выбрать именно перемещение.
Теперь можно удалить фильтр с колонки частотности, чтобы остались запросы только с частотностью 30 и выше.

Определенный этап автоматической чистки мы выполнили. Дальше придется повозиться, удалив мусорные фразы.
Сначала предлагаю указать стоп-слова, чтобы удалить все фразы с их наличием. В идеале конечно же это делается сразу на этапе парсинга, чтобы в список они и не попадали, но это не критично, так как очищение от стоп-слов происходит в автоматическом режиме с помощью Кейколлектора.
Основная сложность состоит в составлении списка стоп-слов, т.к. в каждой тематике они разные. Поэтому, делали бы мы чистку от стоп-слов в начале или сейчас – не так важно, так как стоит найти все стоп-слова, а это дело наживное и не такое уж и быстрое.
В интернете вы можете найти общетематические списки, в которые входят самые распространенные слова по типу «реферат, бесплатно, скачать, п…рно, онлайн, картинка и т.д.».
Сначала предлагаю применить общетематический список, чтобы количество фраз еще уменьшилось. На вкладке «Сбор данных» жмете на кнопку «Стоп-слова» и добавляете их списком.
В этом же окне жмем на кнопку «Отметить фразы в таблице», чтобы отметились все фразы, содержащие введенные стоп-слова. Но нужно, чтобы весь список фраз в группе был не отмечен, чтобы после нажатия на кнопку остались отмечены только фразы со стоп-словами. Снять отметки со всех фраз очень просто.

Когда останутся отмеченные только фразы со стоп-словами, мы ух либо удаляем, либо переносим в новую группу. Я в первый раз удалил, но все таки приоритетней создать группу «Со стоп-словами» и переместить в нее все лишние фразы.
После очистки, фраз стало еще меньше. Но и это не все, т.к. все равно мы что-то упустили. Как сами стоп-слова, так и фразы, не относящие к направленности нашего сайта. Это могут быть коммерческие запросы, под которые тексты не напишешь или же напишешь, но они не будут соответствовать ожиданиям пользователя.
Примеры таких запросов могут быть связаны со словом «купить». Наверняка, когда пользователь что-то ищет с этим словом, то он уже хочет попасть на сайт, где это продают. Мы же напишем текст под такую фразу, но посетителю он нужен не будет. Поэтому, такие запросы нам не нужны. Их мы ищем в ручном режиме.
Оставшийся список запросов мы не спеша и внимательно листаем до самого конца в поисках таких фраз и обнаружения новых стоп-слов. Если обнаружили какое-то слово, употребляющееся много раз, то просто добавляем его в уже существующий список стоп-слов и жмем на кнопку «Отметить фразы в таблице». В конце списка, когда по ходу ручной проверки мы отметили все ненужные запросы, удаляем отмеченные фразы и первый этап составления семантического ядра окончен.
Получили определенное семантическое ядро. Оно еще не совсем полное, но уже позволит написать максимально возможную часть текстов.
Осталось лишь добавить к нему еще небольшую часть запросов, которую мы могли упустить. В этом помогут следующие этапы.
Этап 2 – конкуренты
В самом начале мы собрали список общих фраз, относящихся к нише. В нашем случае это были:
- Заболевания сердца
- Инфаркт;
- Ишемическая болезнь сердца;
- Аритмия;
- Гипертония;
- Порок сердца;
- Стенокардия и т.д.
Все они относятся именно к нише «Болезни сердца». По этим фразам необходимо в поиске найти сайты конкурентов именно по данной теме.
Вбиваем каждую из фраз и ищем конкурентов. Важно, чтобы это были не общетематические (в нашем случае медицинские сайты общей направленности, т.е. про все болезни). Нужны именно нишевые проекты. В нашем случае - только про сердце. Ну может быть еще и про сосуды, т.к. сердце связано с сосудистой системой. Мысль, думаю, вы поняли.
Если у нас ниша «Рецепты салатов с мясом», тогда в перспективе только такие сайты и искать. Если их нет, то старайтесь найти сайты только про рецепты, а не в общем про кулинарию, где все обо всем.
Если же общетематический сайт (общемедицинский, женский, про все виды стройки и ремонта, кулинария, спорт), тогда придется очень помучиться, как в плане составления самого семантического ядра, т.к. придется долго и нудно пахать – собирать основной список запросов, долго ждать процесса парсинга, чистить и группировать.
Если на 1й, а иногда и даже на 2й странице, не удается найти узкие тематические сайты конкурентов, тогда попробуйте использовать не основные запросы, которые мы сформировали перед самим парсингом на 1м этапе, а запросы уже из всего списка после парсинга. Например:
- Как лечить аритмию народными средствами;
- Симптомы аритмии у женщин и так далее.
Дело в том, что такие запросы (аритмия, болезни сердца, порок сердца…) имеют самую высокую конкурентность и по ним выбиться в ТОП практически нереально. Поэтому, на первых позициях, а может быть и на страницах, вы вполне реально найдете только общетематические порталы обо всем в виду их огромнейшей авторитетности в глазах поисковых систем, возраста и ссылочной массы.
Так что вполне разумно использовать для поиска конкурентов более низкочастотные фразы, состоящие из большего количества слов.
Нужно спарсить их запросы. Можно использовать сервис SpyWords, но функция анализа запросов в нем доступна на платном тарифе, стоимость которого довольно большая. Поэтому для одного ядра нет смысла обновлять тариф на этом сервисе. Если нужно собрать несколько ядер на протяжении месяца, например 5-10, тогда можно купить аккаунт. Но опять же – только при наличии бюджета на тариф PRO.
Также можно использовать статистику Liveinternet, если она открыта для просмотра. Очень часто владельцы делают ее открытой для рекламодателей, но закрывают раздел «поисковые фразы», а именно он нам и нужен. Но все же имеются сайты, когда этот раздел открыт для всех. Очень редко, но имеются.
Самым простым способом является банальный просмотр разделов и карты сайта. Иногда мы можем упустить не только какие-то общеизвестные фразы ниши, но и специфические запросы. На них может и не так много материалов и под них не создашь отдельный раздел, но пару десятков статей они могут прибавить.
Когда мы нашли еще список новых фраз для сбора, запускаем тот же сбор поисковых фраз из левой колонки Яндекс Вордстат, как и на первом этапе. Только запускаем мы его уже, находясь во второй группе «Конкуренты», чтобы запросы добавлялись именно в нее.
- После парсинга собираем точные частотности поисковых фраз;
- Задаем фильтр и перемещаем (удаляем) запросы с частотностью менее 30 в отдельную группу;
- Чистим от мусора (стоп-слова и запросы, не относящиеся к нише).
Итак, получили еще небольшой список запросов и семантическое ядро стало более полным.
Этап 3 – расширение
У нас уже есть группа с названием «1-2». В нее мы копируем фразы из групп «Основной список запросов» и «Конкуренты». Важно именно скопировать, а не переместить, чтобы в предыдущих группах все фразы на всякий случай остались. Так будет безопасней. Для этого в окне переноса фраз нужно выбрать вариант «копирование».
Получили все запросы с 1-2 этапов в одной группе. Теперь нужно оставить в этой группе всего 10% самых частотных запросов от всего количества и которые содержат не менее 2х слов. Также их должно быть не более 100 штук. Уменьшаем, чтобы не закопаться в процесс сбора ядра на месяц.
Сперва применяем фильтр, в котором зададим условие, чтобы показывались минимум 2х словные фразы.

Отмечаем все фразы в оставшемся списке. Нажав на колонку «Частотность!», сортируем фразы по убыванию количества показов, чтобы в верху были самые частотные. Далее выделяем первые 10% из оставшегося числа запросов, снимаем с них отметку (правая кнопка мыши – снять отметку с выделенных строк) и удаляем отмеченные фразы, чтобы остались только эти 10%. Не забываем, что если ваши 10% будут более 100 слов, тогда на 100й строке останавливаемся, больше не нужно.
Теперь проводим расширение с помощью функции кейколлектора. Поможет в этом сервис Rookee.

Параметры сбора указываем, как на скриншоте ниже.

Сервис соберет все расширения. Среди новых фраз могут быть очень длинные ключи, а также символы, поэтому не для всех получится собрать частотность через Яндекс Директ. Придется потом дособрать статистику с помощью кнопки от вордстата.
После получения статистики убираем запросы с месячными показами менее 30 и проводим чистку (стоп-слова, мусор, неподходящие к нише ключи).
Этап закончен. Получили еще список запросов.
Этап 4 – сбор лучших словоформ
Как говорил ранее, целью не является определить такую форму фразы, которая будет более правильной.
В большинстве случаев (исходя из моей практики) сбор лучших словоформ укажет на ту же фразу, что и имеется в списке запросов. Но, без сомнения, будут и такие запросы, к которым будет указана новая словоформа, которой еще нет в семантическом ядре. Это дополнительные ключевые запросы. Этим этапом мы добиваем ядро до максимальной полноты.
При сборе своего ядра данный этап дал еще 107 дополнительных запросов.
Сперва мы копируем ключи в группу «1-3» из групп «Основные запросы», «Конкуренты» и «1-2». Должна получиться сумма всех запросов со всех ранее проделанных этапов. Далее используем сервис Rookee по той же кнопке, что и делали расширение. Только выбираем другую функцию.

Начнется сбор. Фразы будут добавляться в новую колонку «Лучшая форма фразы ».

Лучшая форма будет определена не ко всем фразам, так как сервис Rookee попросту не знает все лучшие формы. Но ля большинства результат будет положительным.
Когда процесс окончен, нужно добавить эти фразы ко всему списку, чтобы они находились в той же колонке «Фраза». Для этого выделяете все фразы в колонке «Лучшая форма фразы», копируете (правая кнопка мыши - копировать), далее жмете на большую зеленую кнопку «Добавить фразы» и вносите их.
Убедиться в том, что фразы появились в общем списке очень просто. Так как при подобном добавлении фраз в таблицу происходит в самый низ, то листаем в самый низ списка и в колонке «Источник» мы должны видеть иконку кнопки добавления.

Фразы, добавленные с помощью расширений, будут помечены иконкой руки.
Так как частотность для лучших словоформ не определена, то нужно это сделать. Аналогично предыдущим этапам выполняем сбор количества показов. Не бойтесь, что сбор осуществляем в той же группе, где находятся остальные запросы. Сбор просто продолжится для тех фраз, которые имеют пустые ячейки.
Если вам будет удобней, тогда изначально вы можете добавить лучшие словоформы не в ту же группу, где они и были найдены, а в новую, чтобы там были только они. И уже в ней собрать статистику, очистить от мусора и так далее. А уже потом оставшиеся нормальные фразы добавить ко всему списку.
Вот и все. Семантическое ядро сайта собрано. Но работы еще осталось немало. Продолжаем.
Перед следующими действиями нужно выгрузить все запросы с необходимыми данными в excel файл на компьютер. Настройки экспорта мы выставили ранее, поэтому можно сразу его и сделать. За это отвечает пиктограмма экспорта в главном меню KeyCollector.

Открыв файл, должны получить 4 колонки:
- Фраза;
- Источник;
- Частотность!;
- Лучшая форма фразы.
Это наше итоговое семантическое ядро, содержащее максимальный чистый и необходимый список запросов для написания будущих текстов. В моем случае (узкая ниша) получилось 1848 запросов, что равняется приблизительно 250-300 материалам. Точно сказать не могу - полностью еще на разгруппировал все запросы.
Для немедленного применения это еще сырой вариант, т.к. запросы находятся в хаотичном порядке. Нужно еще раскидать их по группам, чтобы в каждой были ключи к одной статье. Это и является окончательной целью.
Разгруппировка семантического ядра
Этот этап выполняется довольно быстро, хотя и с некоторыми сложностями. Поможет нам сервис http://kg.ppc-panel.ru/ . Имеются и другие варианты, но будем использовать этот в виду того, что с ним мы сделаем все в соотношении качество/скорость. Тут нужна не скорость, а в первую очередь качество.
Очень полезной вещью сервиса является запоминание всех действий в вашем браузере по кукам. Если даже, вы закроете эту страницу или браузер в целом, то все сохранится. Таким образом нет нужды делать все за один раз и бояться, что в один момент может все пропасть. Продолжить можно в любое время. Главное не чистить куки браузера.
Пользование сервисом я покажу на примере нескольких выдуманных запросов.
Переходим на сервис и добавляем все семантическое ядро (все запросы из excel файла), экспортированное ранее. Просто копируем все ключи и вставляем их в окно, как показано на изображении ниже.
Они должны появится в левой колонке «Ключевые слова».
На наличие закрашенных групп в правой стороне не обращайте внимание. Это группы из моего предыдущего ядра.
Смотрим на левую колонку. Имеется добавленный список запросов и строка «Поиск/фильтр». Фильтром мы и будем пользоваться.
Технология очень проста. Когда мы вводим часть какого-то слова или фразы, то сервис в режиме реального времени оставляет в списке запросов только те, что содержат введенное слово/фразу в самом запросе.
Более наглядно смотрите ниже.

Я хотел найти все запросы, относящиеся к аритмии. Ввожу слово «Аритмия» и сервис автоматически оставляет в списке запросов только те, что содержат введенное слово или его часть.
Фразы переместятся в группу, которая будет называться одной из ключевых фраз этой группы.
Получили группу, где лежат все ключевые слова по аритмии. Чтобы увидеть содержимое группы, кликните на нее. Немного позже мы будем эту группу еще разбивать на более мелкие группы, так как с аритмией есть очень много ключей и все они под разные статьи.
Таким образом на начальном этапе группировки нужно создать большие группы, которые объединяют большое количество ключевых слов из одного вопроса ниши.
Если взять в пример ту же тематику сердечных болезней, тогда сначала я буду создавать группу «аритмия», потом «порок сердца», затем «инфаркт» и так далее пока не будет групп по каждой из болезни.
Таких групп, как правило, будет практически столько же, сколько и основных фраз ниши, сгенерированных на 1м этапе сбора ядра. Но в любом случае, их должно быть больше, так как имеются еще фразы с 2-4го этапов.
Некоторые группы могут содержать вообще 1-2 ключа. Это может быть связано, например с очень редким заболеванием и про него никто не знает или никто не ищет. Поэтому и запросов нет.
В общем, когда основные группы созданы, необходимо их разбить на более мелкие группы, которые и будут использованы для написания отдельных статей.
Внутри группы напротив каждой ключевой фразы есть крестик, нажав на который, фраза удаляется из группы и обратно попадает в неразгруппированный список ключевых слов.
Таким образом и происходит дальнейшая группировка. Покажу на примере.
На изображении вы можете видеть, что имеются ключевые фразы, связанные с лечением аритмии. Если мы хотим их определить в отдельную группу для отдельной статьи, тогда удалям их из группы.

Они появятся в списке левой колонки.
Если в левой колонке еще присутствуют фразы, тогда, чтобы найти удаленные ключи из группы, придется применить фильтр (воспользоваться поиском). Если же список полностью находится по группам, тогда там будут только удаленные запросы. Мы их отмечаем и жмем на «Создать группу».

В колонке «Группы» появится еще одна.
Таким образом мы распределяем все ключи по темам и под каждую группу в конечно итоге пишется отдельная статья.
Единственная сложность сего процесса заключается в анализе необходимости разгруппировки некоторых ключевиков. Дело в том, что имеются ключи, которые по своей сути разные, но они не требуют написания отдельных текстов, а пишется подробный материал по многих вопросам.
Это ярко выражено именно в медицинской тематике. Если взять пример с аритмией, то нет смысла делать ключи «аритмия причины» и «аритмия симптомы». Ключи про лечение аритмии еще под вопросом.
Узнается это после анализа поисковой выдачи. Заходим в поиск Яндекса и вбиваем анализируемый ключ. Если видим, что в ТОПе находятся статьи, посвященные только симптомам аритмии, тогда данный ключ выделяем в отдельную группу. Но, если же тексты в ТОПе раскрывают все вопросы (лечение, причины, симптомы, диагностика и так далее), тогда разгруппировка в данном случае не нужна. Все эти темы раскрываем в рамках одной статьи.
Если в Яндексе находятся именно такие тексты на верхушке выдачи, тогда это знак, что разгруппировку делать не стоит.
Тоже самое можно привести на примере ключевой фразы «причины выпадения волос». Могут быть подключи «причины выпадения волос у мужчин» и «…у женщин». Очевидно, что под каждый ключ можно написать отдельный текст, если исходить из логики. Но о чем скажет Яндекс?
Вбиваем каждый ключ и смотрим, какие же тексты там присутствуют. Под каждый ключ там отдельные подробные тексты, тогда ключи разгруппированием. Если же в ТОПе по обеим запросам находятся общие материалы по ключу «причины выпадения волос», внутри которого раскрыты вопросы касаемо женщин и мужчин, тогда оставляем ключи в рамках одной группы и публикуем один материал, где раскрываются темы по всем ключам.
Это важно, так как поисковая система не зря определяет тексты в ТОП. Если на первой странице находятся исключительно подробные тексты по определенному вопросу, тогда велика вероятность, что разбив большую тему на подтемы и написав по каждой материал, вы не попадаете в ТОП. А так один материал имеет все шансы получить хорошие позиции по всем запросам и собирать по ним хороший трафик.
В медицинских тематиках этому моменту нужно уделять много внимания, что значительно усложняет и замедляет процесс разгруппировки.
В самом низу колонки «Группы» имеется кнопка «Выгрузить». Жмем на нее и получаем новую колонку с текстовым полем, содержащим все группы, разделенные между собой строчным отступом.
Если не все ключи находятся в группах, то в поле «Выгрузка» пробелов между ними не будет. Они появляются только при полностью выполненной разгруппировке.
Выделяем все слова (комбинация клавиш Ctrl+A), копируем их и вставляем в новый excel файл.
Ни в коем случае не жмем на кнопку "Очистить все", так как удалится абсолютно все, что вы проделали.
Этап разгруппировки окончен. Теперь можно смело писать по тексту под каждую группу.
Но, для максимальной эффективности, если бюджет вам не позволяет выписать все сем. ядро за пару дней, а имеется лишь строго ограниченная возможность для регулярной публикации небольшого количества текстов (10-30 в месяц, к примеру), тогда стоит определить конкуренцию всех групп. Это важно, так как группы с наименьшей конкуренцией дают результат в первые 2-3-4 месяца после написания без каких-либо ссылок. Достаточно лишь написать качественный конкурентноспособный текст и правильно его оптимизировать. Дальше за вас все сделает время.
Определение конкуренции групп
Сразу хочу отметить, что низко-конкурентный запрос или группа запросов не означает, что они являются сильно микро низкочастотными. Вся прелесть и есть в том, что достаточно приличное количество запросов, которые имеют низкую конкуренцию, но при этом обладают высокой частотностью, что сразу же дает выход такой статье в ТОП и привлечение солидного трафика на один документ.
Например, вполне реальная картина, когда группа запросов имеет конкуренцию 2-5, а частотность порядка 300 показов в месяц. Написав всего 10 таких текстов, после выхода их в ТОП, мы будем получать 100 посетителей ежедневно минимум. И это всего 10 текстов. 50 статей – 500 посещений и эти цифры взяты и потолка, так как это берется в учет лишь трафик по точным запросам в группе. Но привлекаться же трафик будет еще и по другим хвостам запросов., а не только по тем, что находятся в группах.
Вот почему так важно определить конкуренцию. Иногда вы можете видеть ситуацию, когда на сайте 20-30 текстов, а уже 1000 посещений. И причем сайт молодой и ссылок нет. Теперь вы знаете, с чем это связано.
Конкуренцию запросов можно определять через тот же KeyCollector абсолютно бесплатно. Это очень удобно, но в идеале данный вариант не являются правильным, так как формула определения конкурентности постоянно меняется с изменением алгоритмов поисковых систем.
Лучше определять конкуренцию с помощью сервиса http://mutagen.ru/ . Он платный, но более максимально приближенный к реальным показателям.
100 запросов стоят всего 30 рублей. Если у вас ядро на 2000 запросов, тогда вся проверка обойдется в 600 рублей. В сутки дается 20 бесплатных проверок (только тем, кто пополнил баланс на любую сумму). Можете каждый день оценивать по 20 фраз, пока не определите конкурентность всего ядра. Но это очень долго и глупо.
Поэтому, я пользуюсь именно мутагеном и ни имею к нему никаких претензий. Иногда бывают проблемы, связанные со скоростью обработки, но это не так критично, так как даже закрыв страницу сервиса, проверка продолжается в фоновом режиме.
Сам анализ сделать очень просто. Регистрируемся на сайте. Пополняем баланс любым удобным способом и по главному адресу (mutagen.ru) доступна проверка. В поле водим фразу и она сразу же начинает оцениваться.
Видим, что по проверяемому запросу конкурентность оказалась более 25. Это очень высокий показатель и может равняться любому числу. Сервис не отображает его реальным, так как это не имеет смысла в виду того, что такие конкурентные запросы практически нереально продвинуть.
Нормальный уровень конкуренции считается до 5. Именно такие запросы легко продвигаются без лишних телодвижений. Чуть более высокие показатели тоже вполне приемлемы, но запросы со значениями более 5 (например, 6-10) стоит использовать после того, как уже написали тексты под минимальную конкурентность. Важен максимально быстрый текста в ТОП.
Также во время оценки определяется стоимость клика в Яндекс.Директ. По ней можно оценить ваш будущий заработок. Во внимание берем гарантированные показы, значение которых можем смело делить на 3. В нашем случае можно сказать, что один клик по рекламе Яндекс директа нам будет приносить 1 рубль.
Сервис определяет и количество показов, но на них мы не смотрим, так как определяются частотность не вида "!запрос", а только "запрос". Показатель получается не точным.
Такой вариант анализа подойдет, если мы хотим проанализировать отдельный запрос. Если нужна массовая проверка ключевых фраз, тогда на главной странице сверху поля ввода ключа имеется специальная ссылка.

На следующей странице создаем новое задание и добавляем список ключей из семантического ядра. Берем их из того файла, где ключи уже разгруппированы.
Если на балансе достаточно средств для анализа, проверка сразу начнется. Продолжительность проверки зависит от количества ключей и может занять некоторое время. 2000 фраз я анализировал порядка 1го часа, когда во второй раз проверка всего 30 ключей заняла аж несколько часов.
Сразу после запуска проверки вы увидите задание в списке, где будет колонка "Статус". По ней вы и поймете, готово ли задание или нет.
Кроме этого после выполнения задания вы сразу сможете скачать файл со список всех фраз и уровнем конкуренции для каждой. Фразы будут все в таком порядке, как они и были разгруппированы. Единственное, будут удалены пробелы между группами, но это не страшно, т.к.все будет интуитивно понятно, ведь каждая группа содержит ключи на другую тему.
Кроме этого, если задание еще не выполнилось, вы можете зайти внутрь самого задания и посмотреть результаты конкуренции для уже выполненных запросов. Просто нажмите на название задания.
В пример покажу результат проверки группы запросов для семантического ядра. Собственно, эта та группа, под которую писалась данная статья.
Видим, что практически все запросы имеют максимальную конкуренцию 25 или же ближе к ней. Это значит, что по этим запросам, мне либо вообще не видать первых позиций или же не видать их очень долго. Такой материал бы на новом сайте я вообще не писал.
Сейчас же я его опубликовал только для создания качественного контента на блог. За цель конечно ставлю вывести в топ, но это уже позже. Если на первую страницу хотя бы лишь по главному запросу мануал и выйдет, тогда я уже могу рассчитывать не солидный трафик только на эту страницу.
Последним шагом осталось создать окончательный файл, на который мы и будем смотреть в процессе наполнения сайта. Семантическое ядро сайта то уже собрано, но вот управляться с ним не совсем удобно пока.
Создание финального файла со всеми данными
Нам снова понадобится KeyCollector, а также последний файл excel, который мы получили с сервиса mutagen.
Открываем ранее полученный файл и видим примерно следующее.
Из файла нам потребуются только 2 колонки:
- ключ;
- конкуренция.
Можно просто удалить все остальное содержимое из этого файла, чтобы остались только необходимые данные или же создать совсем новый файл, сделать там красивую строку заголовка с наименованием колонок, выделив ее, например, зеленым цветом, и в каждую колонку скопировать соответствующие данные.
Далее копируем все семантическое ядро из этого документа и снова добавляем его в кейколлектор. Потребуется заново собрать частотности. Это нужно, чтобы собрались частотности в таком порядке, как и расположены ключевые фразы. Ранее мы их собирали, чтобы отсеять мусор, а сейчас для создания финального файла. Фразы конечно же добавляем в новую группу.
Когда частотности собраны, мы экспортируем файл из весь столбик с частотностью копируем в финальный файл, где будут 3 колонки:
- ключевая фраза;
- конкурентность;
- частотность.
Теперь осталось немного посидеть и для каждой группы посчитать:
- Средний показатель частотности группы - важен не показатель каждого ключа, а средний показатель группы. Считается, как обычное среднеарифметическое (в excel - функция "СРЗНАЧ");
- Общую частотность группы поделить на 3, чтобы привести возможный трафик к реальным цифрам.
Чтобы вам не мучиться с освоением расчетов в excel, я подготовил для вас файл, куда вам просто в нужные колонки нужно внести данные и все будет посчитано на полном автомате. Каждую группу нужно рассчитывать в отдельности.
Внутри будет простой пример расчета.
Как видите, все очень просто. Из финального файла просто копируете все фразы группы целиком со всеми показателями и вставляете в этот файл на место предыдущих фраз с их данными. И автоматически произойдет расчет.
Важно, чтобы колонки в финальном файле и в моем были именно в таком порядке. Сначала фраза, потом частотность, а уже потом только конкуренция. Иначе, насчитаете ерунду.
Далее придется немного посидеть, чтобы создать еще один файл или лист (рекомендую) внутри файла со всеми данными о каждой группе. Этот лист будет содержать не все фразы, а лишь главную фразу группы (по ней мы будем определять, что за группа) и посчитанные значения группы из моего файла. Это своего рода окончательный файл с данными о каждой группе с посчитанными значениями. На него я и смотрю, когда выбирают тексты для публикации.
Получится все те же 3 колонки, только без каких-либо подсчетов.
В первую мы вставляем главную фразу группы. В принципе, можно любую. Она нужна лишь для того, чтобы ее скопировать и через поиск найти местоположение всех ключей группы, которые находятся на другом листе.
Во вторую мы копируем посчитанное значение частотности из моего файла, а в третью - среднее значение конкуренции группы. Берем мы эти числа из строки "Результат".
В итоге получится следующее.
Это 1й лист. На втором листе находится все содержимое финального файла, т.е. все фразы с показателями их частотности и конкуренции.
Теперь мы смотрим на 1й лист. Выбираем максимально "рентабельную" группу ключей. Копируем фразу из 1й колонки и находим ее с помощью поиска (Ctrl+F) во втором листе, где рядом с ней будут находиться остальные фразы группы.
Вот и все. Мануал подошел к концу. На первый взгляд все очень сложно, но на самом деле - достаточно просто. Как уже говорил в самом начале статьи - стоит лишь начать делать. В будущем я планирую сделать видео-мануал по этой инструкции.
Ну а на этой ноте я заканчиваю инструкцию.
Все, друзья. Буду какие-то пожелания, вопросы - жду в комментариях. До связи.
P. S. Рекорд по объему контента. В Word получилось более 50 листов мелким шрифтом. Можно было не статью публиковать, а создать книгу.
С уважением, Константин Хмелев!
В закладки
Как собрать правильное семантическое ядро
Если вы думаете, что собрать правильное ядро способен некий сервис или программа, то вы будете разочарованы. Единственный сервис, способный собрать правильную семантику, весит около полутора килограмм и потребляет около 20 ватт мощности. Это мозг.
Причем в этом случае у мозга есть вполне конкретное практическое применение вместо абстрактных формул. В статье я покажу редко обсуждаемые этапы процесса сбора семантики, которые невозможно автоматизировать.
Существует два подхода к сбору семантики
Подход первый (идеальный):
Плюсы: в этом случае вы получаете 100% охват - вы взяли все реальные запросы с трафиком по главному запросу «заборы» и выбрали оттуда всё, что вам нужно: от элементарного «заборы купить» до неочевидного «установка бетонных парапетов на забор цена».
Минусы: прошло два месяца, а вы только закончили работать с запросами.
Подход второй (механический):
Бизнес-школы, тренеры и агентства по контексту долго думали, что с этим делать. С одной стороны, действительно проработать весь массив по запросу «заборы» они не могут - это дорого, трудозатратно, людей не получится научить этому самостоятельно. С другой стороны, деньги учеников и клиентов тоже надо как-то забрать.
Так было придумано решение: берем запрос «заборы», умножаем на «цены», «купить» и «монтаж» - и вперед. Ничего не надо парсить, чистить и собирать, главное - перемножить запросы в «скрипте-перемножалке». При этом возникающие проблемы мало кого волновали:
- Все придумывают плюс-минус одинаковые перемножения, поэтому запросы вида «монтаж заборов» или «заборы купить» моментально «перегреваются».
- Тысячи качественных запросов вида «заборы из профнастила в Долгопрудном» вообще не попадут в семантическое ядро.
Подход с перемножениями себя полностью исчерпал: наступают трудные времена, победителями выйдут только те компании, которые смогут для себя решить проблему качественной обработки действительно большого реального семантического ядра - от подбора базисов до очистки, кластеризации и создания контента для сайтов.
Задача этой статьи - научить читателя не только подбирать правильную семантику, но и соблюдать баланс между трудозатратностью, размером ядра и личной эффективностью.
Что такое базис и как искать запросы
Для начала договоримся о терминологии. Базис - это некий общий запрос. Если вернуться к примеру выше, вы продаете любые заборы, значит, «заборы» - главный для вас базис. Если же вы продаете только заборы из профнастила, то вашим главным базисом будет «заборы из профнастила».
В то же время по запросу «заборы из профнастила » - только 127 тысяч показов, то есть охват сжался в десять раз. Сопоставимым образом уменьшится и количество запросов, и трафик на сайт.
Таким образом, можно сказать, что базис - это общий запрос, описывающий товар, услугу или нечто иное, за счет самой своей формулировки определяющий меру охвата потенциальной аудитории.
- Описывают товар или услугу.
- Дадут такой объем расширенных запросов, который вы можете обработать в приемлемые для себя сроки.
Теперь попробуем разобраться с проблемой поиска базисов как таковых.
1. Как вы сами называете товар или услугу
Если вы - подрядчик, то спросите об этом у клиента. Например, заказчик говорит вам: «Я продаю спортивные покрытия в Москве и области». Выбросьте из формулировки заказчика Москву и область, а также подберите синонимы.
Базисы в таком случае будут такими
Цифры - это данные частотности по Москве и области по WordStat. Нетрудно заметить, что каждый из запросов при парсинге WordStat в глубину даст разную выборку расширенных запросов, и каждая выборка - это сегмент целевого спроса.
Пример с синонимами посложнее: «небольшой» медиаплан на сотню с лишним базисов с частотностью по Москве для продажи элитной недвижимости:
Вывод: собирать семантику сложно. Но сам сбор низкочастотных запросов довольно прост - есть куча сервисов от Key Collector до MOAB и других. Дело не в сервисе. Дело в том, что подобрать корректные базисы сервисом невозможно - это можно сделать только руками и мозгом человека, это самая трудная и тяжелая операция.
Итак, мы уже вспомнили определения товара или услуги «из головы» и привели их к укороченным формам. То есть если мы продаем «грузовики камаз», то пишем в файл просто - «камаз».
Важно понять ключевой принцип - выборка по запросу «камаз» и по запросу «65115 -камаз» дает разные запросы, частично непересекающиеся. Это разные сущности.
Поэтому не нужно мучительно читать тайтлы конкурентов или анализировать их в сомнительных сервисах. Расслабьтесь, включите фантазию, налейте бокал хорошего коньяка и почитайте сайты конкурентов. Вот список артикулов, каждый из которых - отдельная выборка.
3. Сервисы поисковых систем
Пример: в правой колонке WordStat содержатся так называемые запросы, которые пользователи искали вместе с указанным. Глядя на правую колонку по запросу из примера выше, можно увидеть запрос с вхождением слова «самосвал».
Отлично. Запрос «купить камаз самосвал» нам не нужен, так как он и так попадет в расширенные запросы по базису «камаз», а вот запрос «самосвал » - это новый сегмент с отдельными новыми запросами, новым спросом и новой семантикой.
Берем его в проект. Аналогичным образом анализируем и блок «искали вместе с этим» в выдаче «Яндекса» и Google.
Google, к примеру, подсказывает запрос «сельхозник»
Вот что можно получить по нему в WordStat
Проверим, что говорит «Яндекс». Даже если предположить, что вы не продаете ничего, кроме «КамАЗов», то ваши усилия все равно не пропадут даром.
Можно взять запрос «тягач» и получить новый спрос на ваши грузовики и по нему
В целом, думаю, принцип понятен: задача - найти как можно больше целевых базисов, которые выступают инициаторами, драйверами новых длинных семантических хвостов.
Конечно, тут можно дать ещё много советов: посмотреть анкор-файл конкурентов, посмотреть выгрузки из SpyWords или Serpstat. Всё это, конечно, хорошо. Вернее, было бы хорошо, если бы не было так грустно. Потому что в сущности работа еще даже не началась: насобирать каждый может, а попробуйте-ка всё это очистить, сгруппировать и грамотно управлять.
Вышеописанного вполне достаточно, чтобы, имея светлую голову, собрать семантику на порядок качественнее и лучше, чем у 99% ваших конкурентов.
Как не потратить всю жизнь на сбор ключевых слов
Многие спрашивают: как грамотно управлять семантикой, как её «резать». Если вы продаете могильные камни из буйволиного рога в Нарьян-Маре, вы вряд ли столкнетесь с этой проблемой - у вас семантики всегда будет мало. В то же время, в «горячих» популярных тематиках семантики всегда валом: названия брендов, категорий, моделей, их синонимы и так далее.
Мы решаем эту проблему за счет многоуровневой приоритизации семантики.
1. Приоритизация семантики до сбора запросов
Если всё равно остается много - уберите и те разделы, где маржинальность меньше 25-30%, там вы тоже, скорее всего, много не заработаете - максимум немного мелочи в карман плюс покажете производителю больше оборота и выбьете новые скидки. Зарабатывать интересные деньги получается на товарах и услугах с маржой от 30% - не всегда и не везде конечно, но эти цифры я видел десятки раз на самых разных проектах.
2. Сбор базисов и расширенной семантики по ним
Собрали? Все равно получается много? Проранжируйте запросы. Ставьте 1, 2 или 3 рядом с каждым базисом. Заставьте себя это сделать, вот так:
Я специально ограничиваюсь тремя значениями - это просто. Если у вас будет десять уровней приоритета, вы сойдете с ума, думая о том, поставить 6 или 7 конкретному базису, - а так решения очень простые и очевидные.
Кроме того, это помогает структурировать свой бизнес для самого себя - взглянуть на него сквозь призму спроса и маржинальности: фильтруем по столбцу «Приоритет» и видим, что поставили «1» тем базисам, по которым мало спроса.
Значит, надо либо активнее работать с другими товарными направлениями, снижать закупочные цены, либо стимулировать спрос - но это уже другая история.
3. Отсекли всё неприоритетное и всё равно семантики слишком много
Когда говорят про «резать» семантику, те, кто с этим поработал, как правило, имеют в виду удаление низкочастотных запросов с частотностью ниже определённой отсечки. В тематических дискуссиях в Facebook и на форумах я регулярно вижу цифры от 5 до 10 (имеется в виду общая частотность по запросу).
То есть намеренно убирается из массива всё, что по частотности меньше 10.
Понятно, что так делать можно, если у вас всё равно очень много семантики. Но это всегда вопрос выбора между поеданием рыбы и сидением на неудобных для сидения предметах. Слишком много уберете - недосчитаетесь каких-то минус-слов, получите больше «грязного» трафика на запуске, но выиграете в трудозатратности.
Моё мнение таково: условная точка баланса здесь находится на уровне «убираем всё, что не имеет частотности». Это позволяет выкинуть примерно половину массивов, полученных из различных источников, в то же время трафик на запуске остается очень чистым, с погрешностью буквально 1-3% и быстро дочищается.
Что значит «дочищается»
Звонки? Тоже нет, ведь огромное влияние на количество звонков оказывает сайт: может быть, с кампанией всё хорошо, просто сайт сделан неправильно.
Быстро проверить эффективность поисковой кампании можно в «Яндекс.Метрике». Для этого нам надо через два-три дня после запуска кампании получить отчет о фразах, послуживших источниками перехода. Как найти этот отчет в «Метрике»:
Кликаем на крестик на всех группировках, кроме «Поисковая фраза», и нажимаем «Применить». Мы получим отчет о тех фразах, по которым пользователи увидели наши объявления, кликнули по ним и перешли к нам на сайт. Что делать с этим отчетом?
Внимательно просмотреть и выделить нерелевантные фразы, которые не относятся к вашему бизнесу. На жаргоне их называют «мусором». В профессионально сделанных кампаниях в первое время после запуска доля «мусора» может составлять от 1 до 4%, в кампаниях, собранных «на коленке», - до 20-40%.
Как вы уже, наверное, поняли, процедуру с дополнительной очисткой от мусора стоит проводить регулярно - как минимум, два-три раза в месяц. Почему так часто?
У нас был интересный пример из практики. Мы работали с кампанией, в которую включили для клиента высокомаржинальный запрос «черный дым дизель». Клиент работал с дизельными двигателями, и такой запрос означает, что у клиента есть серьезная проблема с двигателем, и, вероятно, потребность в квалифицированных услугах.
Одновременно с этим в сентябре 2016 года, когда группировка российского флота направилась в Сирию, ТАКР «Адмирал Кузнецов» привлек внимание международных СМИ сильным черным дымом из выхлопной трубы. Это неизбежно спровоцировало запросы вроде «черный дым дизель адмирал кузнецов».
Ранее таких запросов просто не было, поэтому и не было минусов формата «–адмирал, –кузнецов». Поэтому мало того, что наше объявление показалось по таким запросам, так оно ещё и сгенерировало бессмысленные переходы, не имеющие для бизнеса никакой ценности.
Отследить такие запросы оперативно можно только в «Метрике»: поэтому возьмите себе за правило на старте кампании почаще (позже - реже) проверять семантику и дополнительно минусовать новый мусор.
Разумеется, возникает вопрос: а что вообще влияет на количество мусора. Всё просто - статистическая достоверность семантики.
На что влияет объем семантики
Далеко не всегда люди понимают, о чем говорят, когда обсуждают влияние обширного семантического ядра на цену клика, качество кампании и прочее. Сама по себе обширная семантика не вызывает ни снижения цены клика, ни увеличения качества кампании. На что же реально влияют сотни и тысячи собранных НЧ-запросов?
1. Чистота трафика на запуске кампании
Чем больше запросов вы соберете - тем больше найдете минус-слов. На бесконечно большой выборке запросов вы найдете все возможные минус-слова, потратив на это бесконечный период времени.
На практике стоит ограничиться запросами, как я уже говорил, с частотностью от 1 по нужному региону - это даст «мусорность» в районе 3-4% при запуске, после чего вы быстро дочистите оставшиеся мусорные запросы, минусы, по которым почему-то не попали в выборку.
При этом стоит использовать и WordStat, и советы поисковых систем, собирая подсказки для каждого запроса, полученного в WordStat. Использование одного только WordStat даст высокую мусорность - 10-15% на запуске как минимум (если не больше). Но все мы понимаем - чем больше мусора, тем больше расход средств, тем меньше лидов на единицу расхода.
2. Релевантность объявлений запросам
Реальный трафик, который будет попадать к вам на сайт, приходит большей частью не по тем запросам, которые вы добавили в кампанию, а по расширениям от них. На один запрос, добавленный в кампанию, приходится как минимум три-четыре расширенных варианта - это ультра-НЧ, которые вообще никак не предскажешь, пользователи генерируют их прямо в момент поиска.
Поэтому не столь важен сам запрос: так много стало трафика по ультра-НЧ с частотой перехода в один-два раза в месяц или в год, что привязываться к конкретному запросу нет смысла. Важно собрать статистически значимую семантику, разбить её на мелкие группы похожих запросов и составить под них объявления.
Больше семантика - больше групп, больше точность соответствий и ниже цена кампаний на поиске. В конкретной группе похожих ультра-НЧ, из которых сформируется объявление, может быть пять-десять запросов - а если вы выудите из «Метрики» фразы по этому объявлению через полгода, получите список на 30-40 фраз как минимум.
Повторюсь: семантика - не панацея от всего и не божество. Семантика влияет на многое: на чистоту трафика, на релевантность объявлений запросам - но не на всё. Не имеет смысла собирать огромные выборки «нулевок» в надежде получить трафик дешевле - этого не будет.
Семантика влияет:
Вот те факторы, про которые вам стоит помнить в первую очередь. Впрочем, попробуем суммировать итоги в двух словах.
Кратко
- Соберите базисные запросы - общие фразы, описывающие ваши товары и услуги.
- Проверьте, все ли синонимы и переформулировки вы собрали: в помощь вам WordStat и блок «похожие запросы» в SERP.
- Соберите расширения по полученным запросам: WordStat, поисковые подсказки, база MOAB - всё идет в дело.
- Составьте табличку, где рядом с каждым базисом будет указана его частотность и количество расширенных запросов.
- Если запросов слишком много, и вы не успеваете их обработать - выполните приоритизацию базисов в зависимости от маржи, частотности и количества запросов.
- Окончательный семантический план сформирован. Теперь дело за очисткой и кластеризацией семантики.
Оптимизация и продвижение сайта всегда начинается с сбора семантического ядра сайта и подбора ключевых слов по тематике сайта, в зависимости от того насколько правильно собранно семантическое ядро, зависит успех продвижения и оптимизации сайта.
Мы подробно рассмотрим как правильно составить семантическое для сайта, какие бывают ошибки при подборе запросов, а так же какие основные инструменты используются для сбора семантики.
Семантическое ядро сайта — это сгруппированные в отдельные категории ключевые запросы (слова) соответствующие тематике вашего сайта и позволяющие пользователям через поисковую систему (Яндекс или Google) найти Ваш сайт в интернете.
Хорошо проработанное семантическое ядро позволит каждой странице вашего ресурса соответствовать определенным запросам пользователей и поможет Вам эффективно продавать свои продукты и услуги, а так же вы сможете привлечь целевую аудитории на сайт.

ВАЖНО! К составлению семантики сайта необходимо подойти очень ответственно и скрупулезно, так как выбранные ключевые слова, будут применяться при:
- внутренней оптимизации сайта (перелинковка, мета теги)
- внешней оптимизации сайта (закупка ссылок)
- составление рекламных компаний (контекстная реклама, социальные сети)
Внимательно читайте статью и не стесняйтесь задавать вопросы в комментариях или писать в социальных сетях, я с удовольствием отвечу на каждый комментарий и вопрос.
Основные понятия и термины
Запросы (ключевые слова) — собираются поисковой системой (Яндекс или Google) для статистики и используются поисковиками при Яндекс Директ или Google AdWords.
Для сбора семантического ядра Вам необходимо определить список услуг и товаров которые вы хотите продвигать, и выбрать по каким именно запросам ваши товары или услуги будут искать пользователи и покупатели.
Первым делом для составления семантики необходимо выписать все самые важные слова характеризующие тематику вашего сайта, далее написать предположительно к каждой категории слов, фразы и словосочетания по которым пользователи могут искать Вас в сети (ваши товары или услуги).

Для более точного сбора ядра запросов необходимо понимать какие виды запросов бывают, и какие виды запросов подойдут Вашему сайту.
К примеру вы оказывает услугу по ремонту сотовых телефонов в определенном районе. Стремиться к тому чтоб Ваш сайт был первым по запросу «ремонт смартфона» бессмысленно и очень дорого, так как по данному запросу очень высокая частотность, но и очень большая конкурентность.
Какие виды запросов бывают
Самое важное значение по которому сортируют запросы Seo оптимизаторы это частотность запросов. Есть 3 основные категории запросов:

Высокочастотные запросы (ВЧ) — самые популярные запросы в основном состоящие из 1- 2 слов и характеризующие тематику в общем. Многие оптимизаторы делят частотность исходя из цифр и начинают ВЧ запросы от 3000 — 5000 тысяч запросов в месяц. Я лично считаю такой подход неподходящим, и характеризую ВЧ запросы как запросы имеющие наибольшую популярность в тематике и характеризующие тематику в целом.
Пример: купить часы (151 759 запросов в месяц по Москве и Московской области) или заказать сайт (14 019 запросов в месяц по Москве и Московской области) .
Среднечастотные запросы (СЧ) — запросы менее популярны и имеют обычно от 2-4 слов, а так же носят более точный характер и направленность как по географическому смыслу так и практическому. Продвижение по среднечастотным запросам на мой взгляд наиболее эффективное и целевое, дает отличный результат.
Пример: купить часы недорого (8 596 запросов в месяц по Москве и Московской области) или заказать сайт дешево (439 запросов в месяц по Москве и Московской области).
Низкочастотные запросы (НЧ) — самые непопулярные запросы состоящие из 4-7 слов и имеющие точный характер запроса и вполне конкретную миссию. Обычно продвижение по низкочастотным запросам, самое эффективное и быстрое, здесь необходимо действовать по принципу, «чем больше, тем лучше».
Пример: где можно купить купить часы недорого (90 запросов в месяц по Москве и Московской области) или где заказать сайт дешево (39 запросов в месяц по Москве и Московской области).
Кроме частотности для правильного сбора семантического ядра для нового сайта, так же необходимо понимать насколько конкурентен запрос. Определить конкурентность запроса можно очень просто.

Введите запрос в поисковую строку и вы уведите количество страниц в базе поисковика соответствующих запросу. Чем выше конкуренция тем сложней попасть в ТОП-10 по данному словосочетанию.
По конкурентности запросы бывают:
- Высококонкурентные (ВК)
- Среднеконкурентные (СК)
- Низкоконкурентные (НК)
Высококконкурентные высокочастотные запросы (ВЧ ВК) одни из самых сложных для продвижения (пример — купить часы), поэтому когда вы создаете семантическое ядро для нового сайта, лучше не тратить время и их не учитывать.
Этапы составления семантического ядра
Всю работу по сбору семантического ядра можно разделит на несколько простых этапов. Прежде чем преступать к созданию семантического ядра, Вам стоит создать в excle файл в который вы выпишите все страницы Вашего сайта, создав тем самым структуру семантического ядра.

Допустим вы занимаетесь продажей оборудования для видеонаблюдения, у Вас большое количество категорий и подкатегорий на сайте, Вам необходимо выписать полностью все категорий и подкатегории в файл.
Пример:
Карманные часы
- механические часы
— механические мужские часы
— механические женские часы- кварцевые часы
- электронные часы
Напольные часы
- механические пружинные
- механические гиревые
Собираем все возможные тематические запросы
Для начала необходимо составить «скелет» ядра запросов, страниц вашего сайта, основные категории товаров и услуг, далее к каждой категории, вы добавляете подкатегории и подразделы.

Вы открываете стандартный инструмент для составления семантики «Яндекс Wordstat » и вводите все предполагаемые ключевые слова подходящие для определенной категории в строку поиска. Выписывая в файл все без исключения слова.
Очень хорошо работать с подбором запросов в Wordstat помогает плагин для браузера Yandex Wordstat Assistant (инструкция прилагается)
Если Ваш сайт имеет региональную принадлежность выберете регион вашего сайта. Это поможет более точно понимать как часто пользователи вводят запросы вашей тематики, в вашем регионе. (Все слова не относящиеся к вашему региону отфильтровывайте и отбрасывайте заранее)
Собирайте все возможные запросы связанные с вашей тематикой и отвечающими контенту ваших страниц. Когда вы собрали все запросы для каждой страницы, можно приступать к следующему этапу.
Отфильтровываем неподходящие и пустые запросы
На данном этапе у вас должен быть большой структурированный файл с сгруппированный по разделам в который собранно большое количество ключевых слов соответствующих тематики Вашего сайта.
Среди отобранных вами ключевых запросов Вам необходимо выбрать и удалить определенные запросы:
- Повторяющиеся ключевые запросы «купить часы» и «часы купить» (оставлять стоит запрос звучащий боле натурально).
- Ключевые слова с опечатками или ошибками «купить часcы» или «купить муржские часы».
- Ключевые запросы с брендом или маркой которые вы не продаете «купить часы apple» или «купить часы смарт».
- Запросы с упоминанием региона в котором вы не представлены «купить часы в Новосибирске», «купить часы Спб» (если вы работает в определенном городе, сразу исключайте данные запросы из списка, оставляя только регион вашего присутствия)
- Удаляйте из запросов слова содержащие названия ваших конкурентов (рекомендую выделить их в отдельный список и рекламироваться по данным запросам в Яндекс Директ, данные запросы будут стоить недорого, а вы сможете частично отнять клиентов у конкурента)
- Общие запросы информационного типа (скачать, бесплатно, б/у, самому, обзор, отзывы) в любой тематике люди ищут инструкции или обзоры по выбору товара, или ищут как сделать бесплатно или скачать какой-то контент, так как ваша цель продажи товаров и услуг данные слова стоит удалить.
После того как вы удалили все вышеперечисленные ключевики и подчистили ваше семантическое ядро, Вам стоит еще раз внимательно посмотреть на весь список и повторить отчистку запросов.
Удаляем общие и высоко конкурентные ключи
Многие высокочастотные и высококонкурентыне слова на практике не приносят прибыли, средства и время потраченное на их продвижение не оправдываются, так как не совсем понятно какую информацию ищет клиент вводя высокочастотный запрос.

Пример: когда пользователь вводит запрос «механические часы», он хочет узнать о том как они работают, или узнать как их ремонтирую, или понять какие часы считаются механическими. Вам сложно это предугадать поэтому такого рода запросы стоит удалять. Самый лучший запрос для Вас это «купить механические часы» или «отремонтировать механические часы».
Поэтому я рекомендую удалить из семантического ядра самые высокочастотные запросы. Так вы сэкономите время и средства вложенные в продвижение сайта. После того как вы удалите все общие ВЧ запросы вы можете считать что ваше семантическое ядро готово.
У Вас должен быть файл со структурой повторяющей структуру сайта и к каждой странице подобраны слова для продвижения.
Сервисы для сбора семантического ядра
Как было уже сказано поисковые системы собирают данные запросов для прогноза бюджета в рекламных сервисах (Яндекс Директ и Google AdWords). Для сбора семантического ядра используют как платные сервисы и отдельные программы, так и бесплатные сервисы от поисковых систем. Мы вкратце рассмотрим каждую из них.
Бесплатные сервисы
Бесплатные сервисы для сбора семантического ядра являются самыми популярными и часто используемыми, у каждой поисковой системы есть свой сервис, но му рассмотрим только два самых популярных.

Яндекс Wordstat — один из самых популярных сервисов позволяющих боле точно узнать какие ключевые запросы использовали пользователи поисковика Яндекс, в нем есть возможность посмотреть «сезонность определенного запроса» и «региональную привязку запроса».

Планировщик ключевых слов (Google AdWords) — с подбором слов в Google все намного интересней и на первый взгляд сложней чем в Wordstat, но вы сможете более детально и развернуто получить информацию о запросе, оценить конкурентность запроса, а так же сразу получить кучу похожих ключей. Многие пользуются как вордстатом так и дополняют запросы планировщиком ключевых слов.

Словоеб — это очень интересный инструмент (отдельная программа) которая распространяется совершенно бесплатно и помогает создавать семантические ядра внутри нее. Полностью структурируя каталог и собирая данные как с Wordstat так и AdWords, гибкая в настройках и очень удобная.
Платные сервисы
Платные программ и сервисы позволяют Вам существенно расширить базу ключевых слов, так ка собирают не только запросы с онлайн сервисов поисковиков, но и учитывают дополнительные данные.

KeyCollector — одна из самых распространенных и популярных программ среди Seo оптимизаторов. Позволяет более эффективно проводить отчистку семантического ядра, и очень полезна при больших ядрах запросов, так как в данной программе можно создать сложную структуру и не запутаться. Лицензия покупается 1 раз и вы пользуетесь ею пожизненно. При постоянном использовании программа на 100% оправдывает вложенные средства.

— онлайн сервис по сбору ключевых слов и составления семантического ядра, вы платите за подписку с несколькими версиями, часто используется Seo оптимизаторами
Ошибки при составлении семантического ядра
В самом конце стоит рассмотреть самые популярные ошибки при сборке сематического ядра:
- не стоит гнаться за высокочастотными запросами — если вы занимаетесь интернет коммерцией продаете товары или поставляете услуги, для вас важно быть в топе по транзакционным вопросам
- не злоупотребляйте информационными запросами -ваша цель не ответить на вопросы пользователя а продать ему свой товар или услугу
- много запросов на одну страницу — 20 ключей на одну страницу это слишком много, если у вас есть такая страница, выделите общие запросы из нее в отдельную страницу и продвигайте две страницы по 10 запросов.
Выводы
Для успешного продвижения и оптимизации сайта (блога) необходимо качественно составить семантическое ядро, если Вам самому не хочется заниматься составлением семантического ядра, я рекомендую обратиться в компанию Семен Ядрен , и заказать семантику них.
Рекомендуем посмотреть видео «Как собрать семантическое ядро для сайта самому»
Сегодня любой бизнес, представленный в Интернете (а таковым является, по сути, любая компания или организация, не желающая терять свою аудиторию клиентов из “онлайна”) уделяет немалое внимание поисковой оптимизации. Это правильный подход, который может помочь существенно сократить расходы на продвижение, уменьшить рекламные затраты и при наступлении должного эффекта создаст новый источник клиентов для бизнеса. В числе инструментов, с помощью которых осуществляется продвижение, находится и составление семантического ядра. О том, что это такое и как работает, мы расскажем в данной статье.
Что представляет собой “семантика”
Итак, начнем мы с общего представления о том, что являет собой и что означает понятие “собрать семантику”. На различных интернет-сайтах, посвященных поисковой оптимизации и продвижению сайтов, описано, что семантическим ядром можно назвать список слов и словосочетаний, которые способны полностью описать его тематику, сферу деятельности и направленность. В зависимости от того, насколько масштабным является данный проект, он может иметь крупное (и не очень) семантическое ядро.
Считается, что задача собрать семантику является ключевой в том случае, если вы хотите начать продвижение своего ресурса в поисковых системах и желаете получать “живой” поисковый трафик. Поэтому нет никаких сомнений в том, что отнестись к этому следует с полной серьезностью и ответственностью. Зачастую правильно собранное семантическое ядро - это существенный вклад в дальнейшую оптимизацию вашего проекта, в улучшение его позиций в “поисковиках” и рост таких показателей, как популярность, посещаемость и прочих.
Семантика в рекламных кампаниях
На самом деле составление списка ключевых слов, которые максимально удачно опишут ваш проект, важно не только в том случае, если вы занимаетесь поисковым продвижением. При работе с в таких системах, как “Яндекс.Директ” и Google Adwords, не менее важно тщательно подбирать те “ключевики”, которые дадут возможность получить самых заинтересованных клиентов в вашей нише.

Для рекламы такие тематические слова (их подбор) важны еще и по той причине, что с их помощью можно находить более доступный трафик из вашей категории. Например, это актуально в том случае, если ваши конкуренты работают лишь по дорогостоящим ключевикам, а вы “обходите” эти ниши и продвигаетесь там, где идет второстепенный для вашего проекта трафик, заинтересованный, тем не менее, в вашем проекте.
Как собрать семантику автоматически?
На самом деле сегодня существуют развитые сервисы, позволяющие составить семантическое ядро для вашего проекта за считанные минуты. Это, в частности, и проект для автоматического продвижения Rookee. Процедура работы с ним описывается в двух словах: вам нужно зайти на соответствующую страницу системы, где предлагается совершить сбор всех данных о ключевых словах вашего сайта. Далее нужно ввести адрес ресурса, интересующего вас в качестве объекта для составления семантического ядра.
Сервис в автоматическом режиме анализирует контент вашего проекта, определяет его ключевые слова, получает те наиболее определяемые фразы и слова, которые содержит проект. За счет этого для вас формируется список из тех слов и фраз, которые можно назвать “основой” вашего сайта. И, по правде говоря, собрать семантику таким образом проще всего; сделать это может каждый. Более того, система Rookee, анализируя подходящие ключевые слова, подскажет вам еще и стоимость продвижения по тому или иному ключевику, а также сделает прогноз относительно того, сколько поискового трафика можно получить в том случае, если будет делаться продвижение по этим запросам.
Ручное составление

Если говорить о подборе ключевиков в автоматическом режиме, на самом деле здесь не о чем долго расписывать: вы просто используете наработки готового сервиса, подсказывающего вам ключевые слова на основании наполнения вашего сайта. На самом деле не во всех случаях результат такого подхода будет устраивать вас на все 100%. Поэтому рекомендуем также обратиться и к ручному варианту. О том, как собрать семантику для страницы своими руками, мы также расскажем в этой статье. Правда, перед этим нужно оставить пару примечаний. В частности, вы должны понимать, что заниматься ручным сбором ключевиков вы будете дольше, чем длится работа с автоматическим сервисом; но при этом вы сможете выделить для себя более приоритетные запросы, исходя не из стоимости или эффективности их продвижения, а ориентируясь в первую очередь на специфику работы вашей компании, ее вектор и особенности предоставляемых услуг.
Определение тематики
Первым делом, говоря о том, как собрать семантику для страницы в ручном режиме, необходимо обратить внимание на тематику компании, ее сферу деятельности. Приведем простой пример: если ваш сайт представляет фирму по продаже запчастей, - то основой его семантики выступят, конечно же, запросы, имеющие наибольшую частоту употребления (что-то вроде “автозапчасти для Ford”).
Как отмечают эксперты по поисковому продвижению, не стоит на данном этапе бояться использовать высокочастотные запросы. Многие оптимизаторы ошибочно полагают, что большая конкуренция наблюдается именно в борьбе за эти часто употребляемые, а значит, и более перспективные запросы. На деле это не всегда так, поскольку отдача от посетителя, пришедшего по конкретному запросу вроде “купить аккумулятор на Ford в Москве” зачастую будет гораздо выше, чем от человека, ищущего какие-то общие сведения об аккумуляторах.
Также важно обратить внимание на какие-то специфические моменты, связанные с работой вашего бизнеса. Например, если ваша компания представлена в сфере оптовых продаж, семантическое ядро должно отображать такие ключевые слова, как “оптом”, “купить оптом” и так далее. Ведь пользователь, который пожелает приобрести ваш товар или услугу в розничном варианте, будет попросту неинтересен вам.
Ориентируемся на посетителя

Следующим этапом нашей работы является ориентация на то, что ищет пользователь. Если вы хотите знать, как собрать семантику для страницы в соответствии с тем, что ищет посетитель, нужно обратиться к ключевым запросам, которые он делает. Для этого существуют такие сервисы, как “Яндекс.Wordstat” и Google Keyword External Tool. Эти проекты служат для вебмастеров ориентиром по поиску интернет-трафика и дают возможность выявить интересные ниши для своих проектов.
Работают они очень просто: нужно в соответствующую форму “вбить” поисковый запрос, на основе которого вы будете искать релевантные, более уточняющие. Таким образом, здесь вам пригодятся те высокочастотные ключевики, которые были установлены в предыдущем этапе.
Фильтрование
Если вы хотите собрать семантику для СЕО, наиболее эффективным для вас подходом будет дальнейшее отсеивание “лишних” запросов, которые окажутся неподходящими для вашего проекта. К таким, в частности, можно отнести какие-то ключевые слова, релевантные вашему семантическому ядру с точки зрения морфологии, но отличающиеся по своей сущности. Сюда же должны войти и ключевые слова, которые не будут должным образом характеризовать ваш проект или будут делать это неправильно.

Поэтому, до того как собрать семантику ключевых слов, необходимо будет избавиться от неподходящих. Делается это очень просто: из всего списка ключевиков, составленного для вашего проекта, нужно выделить ненужные или несоответствующие сайту и просто их удалить. В процессе такой фильтрации вы установите самые подходящие из запросов, на которые будете ориентироваться в дальнейшем.
Кроме смыслового анализа представленных ключевиков, должное внимание также нужно уделить и фильтрованию их по количеству запросов.
Сделать это можно с помощью все тех же Google Keyword Tool и "Яндекс.Wordstat". Забив запрос в форму поиска, вы получите не только дополнительные ключевики, но и узнаете, сколько раз делается тот или иной запрос в течение месяца. Так вы будете видеть примерное количество поискового трафика, которое можно получить через продвижение по этим ключам. Больше всего на этом этапе нас интересует отказ от малоиспользуемых, непопулярных и попросту низкочастотных запросов, продвижение по которым будет для нас лишними расходами.
Распределение запросов по страницам
После того как был получен список самых подходящих для вашего проекта ключевиков, необходимо заняться сопоставлением этих запросов со страницами вашего сайта, которые будут продвигаться по ним. Здесь самое важное - определить то, какая из страниц является максимально релевантной тому или иному запросу. Причем поправку следует делать и на ссылочный вес, присущий той или иной странице. Скажем, соотношение приблизительно такое: чем более конкурентен запрос, тем более цитируемую страницу следует выбирать под него. Это означает, что в работе с самыми конкурентными мы должны использовать главную, а под те, конкуренция в которых меньше, вполне подойдут и страницы третьего уровня вложенности и так далее.

Анализ конкурентов
Не забывайте и о том, что вы всегда можете “подглядеть”, как осуществляется продвижение сайтов, находящихся на “топовых” позициях поисковых систем по вашим ключевым запросам. Однако, до того как собрать семантику конкурентов, необходимо определиться, какие сайты мы можем отнести к этому списку. Не всегда в него войдут ресурсы, принадлежащие вашим конкурентам по бизнесу.
Возможно, с точки зрения поисковых систем, эти компании занимаются продвижением по другим запросам, поэтому обращать внимание рекомендуем на такую составляющую, как морфология. Просто забейте в поисковую форму запросы из своего семантического ядра - и вы увидите своих конкурентов по выдаче. Далее нужно просто сделать их анализ: просмотреть параметры доменных имен этих сайтов, собрать семантику. Что это за процедура, и как просто осуществить ее с помощью автоматизированых систем, мы уже описывали выше.
Помимо всего того, что уже было описано выше, хотелось бы также представить несколько общих советов, которые дают опытные оптимизаторы. Первый - это необходимость заниматься комбинацией высоко- и низкочастотных запросов. Если вы будете ориентироваться только на одну категорию из них, кампания по продвижению может оказаться провальной. В случае если вы выберете только “высокочастотники”, они не дадут вам нужных целенаправленных посетителей, ищущих что-то конкретное. С другой стороны, НЧ-запросы не дадут вам нужного объема посещаемости.
Вы уже знаете, как собрать семантику. Wordstat и Google Keyword Tool вам помогут определить, какие слова ищутся вместе с вашими ключевыми запросами. Однако не стоит забывать еще и об ассоциативных словах и опечатках. Эти категории запросов могут быть очень выгодны, если использовать их в своем продвижении. Как по первым, так и по вторым мы можем добыть определенное количество трафика; а в случае, если запрос будет низкоконкурентным, но целевым для нас, такой трафик окажется еще и максимально доступным.
У некоторых пользователей часто возникает вопрос: как собрать семантику для Google/Yandex? Имеется в виду, что оптимизаторы ориентируются на конкретную поисковую систему, продвигая свой проект. На самом деле такой подход вполне оправдан, однако существенных различий в нем нет. Да, каждая из поисковых систем работает со своими алгоритмами фильтрации и поиска контента, но угадать, где сайт будет ранжироваться выше, достаточно сложно. Можно найти лишь какие-то общие рекомендации по тому, какие следует применять в случае, если вы работаете с той или иной ПС, но универсальных правил тому (тем более - в проверенном и общедоступном виде) нет.
Составление семантики для рекламной кампании
У вас может возникнуть вопрос о том, как собрать семантику для "Директа"? Отвечаем: в целом процедура соответствует той, что была описана выше. Необходимо определиться: каким запросам релевантен ваш сайт, какие страницы заинтересуют пользователя больше всего (и по каким ключевым запросам), продвижение по каким из ключей будет для вас самым выгодным и так далее.

Специфика того, как собрать семантику для "Директа" (или любого другого рекламного агрегатора) заключается в том, что вам нужно категорически отказываться от нетематичного трафика, поскольку стоимость клика гораздо выше, чем в случае с поисковой оптимизацией. Для этого используются “стоп-слова” (или “минус-слова”). Чтобы понять, как собрать семантическое ядро с “минус-словами”, нужны более глубокие познания. В данном случае речь идет о таких словах, что могут привести на ваш сайт неинтересующий вас трафик. Часто такими могут быть слова “бесплатно”, например, - в том случае, когда речь идет об интернет-магазине, в котором априори не может быть ничего бесплатного.
Попробуйте составить семантическое ядро для своего сайта самостоятельно, и вы убедитесь в том, что здесь нет ничего сложного.





